Background
Understanding Machine Learning
Machine Learning is a field of artificial intelligence that empowers computers to learn and make decisions without being explicitly programmed. There are various machine learning algorithms, broadly categorized into supervised and unsupervised learning. In supervised learning, a model learns from labeled training data, while unsupervised learning involves finding patterns in data without explicit labels.
Decision Trees and Boosting Algorithms
Decision trees are a fundamental concept in machine learning. They are flowchart-like structures where each node represents a decision based on a particular feature. Boosting algorithms, like XGBoost, enhance the predictive power of decision trees. They work by combining weak learners to create a strong predictive model. XGBoost, in particular, has proven effective in various applications due to its speed and performance.
Problem Definition
Predicting Concrete Compressive Strength
This tool aims to predict the compressive strength of concrete based on input parameters such as cement, water, coarse aggregate, fine aggregate, fly ash, superplasticizer, blast furnace slag, and age. Compressive strength is influenced by various factors like cement content, water-to-cement ratio, and curing time. Machine learning models, including XGBoost Regressor, were trained to accurately predict concrete compressive strength.
Data Collection
Data Source
The dataset used for training the models is sourced from the UCI Machine Learning Repository. The dataset contains 1030 concrete data samples, each with the following input variables.
- Cement (kg/m3)
- Water (kg/m3)
- Coarse Aggregate (kg/m3)
- Fine Aggregate (kg/m3)
- Superplasticizer (kg/m3)
- Fly Ash (kg/m3)
- Blast Furnace Slag (kg/m3)
- Age (days)
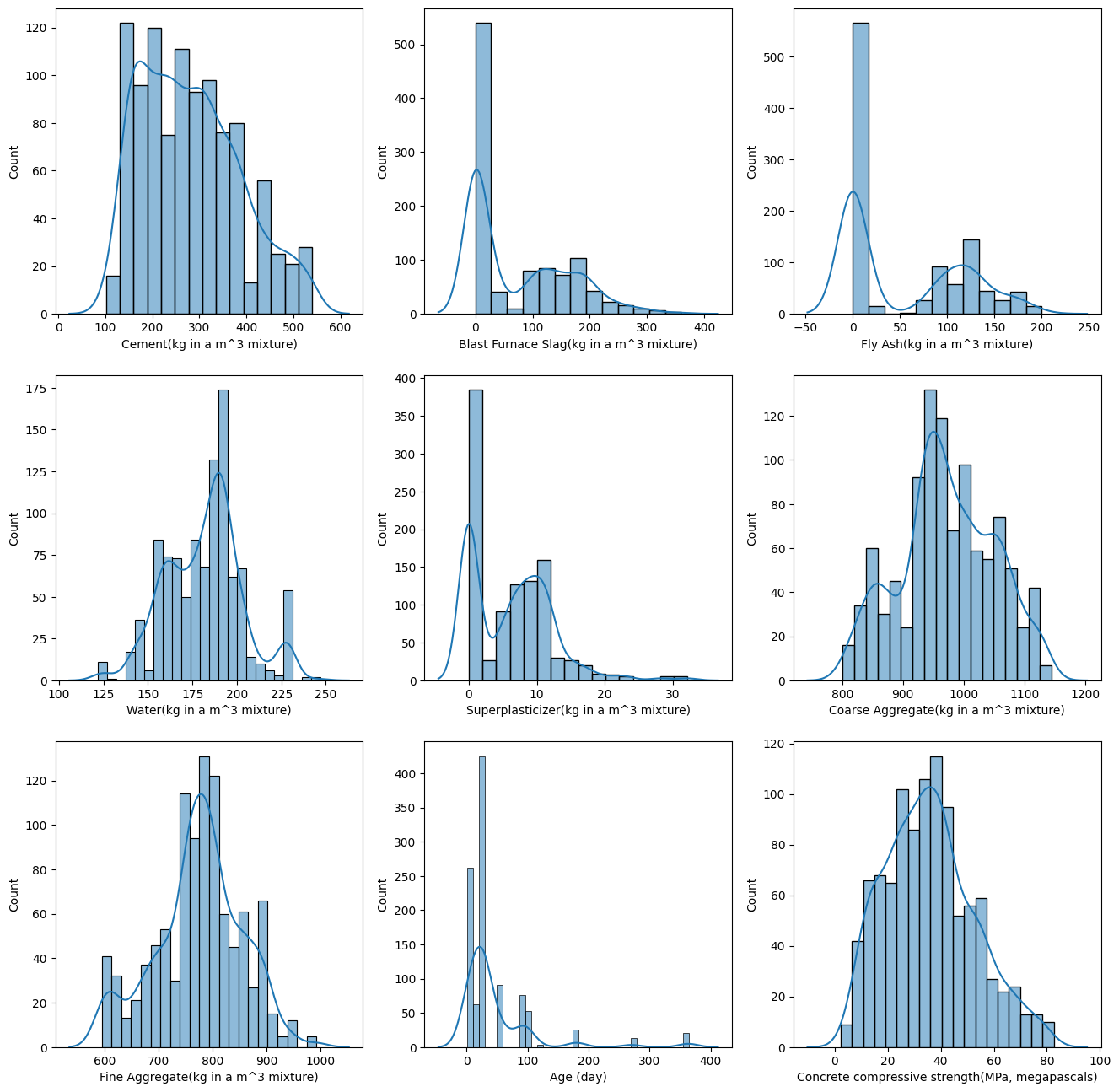
Data Distribution
The following chart illustrates the relative frequency distribution of each parameter in the dataset:
Model Selection and Evaluation
XGBoost Regressor
The XGBoost Regressor was found to be the most accurate model for prediction of compressive strength of concrete. Model selection involved the hold-out method, and the model evaluation process involved tuning hyperparameters, accuracy analysis, and model validation using both hold-out and cross-validation techniques. The following are some of the metrics used to evaluate the model's performance:
- R-squared: This is a measure of how well the model fits the data. It represents the proportion of the variance for a dependent variable that's explained by an independent variable(s) in a regression model. It ranges from 0 to 1, with higher values indicating a better fit.
- Mean-squared Error(MSE): MSE is a measure of the average squared difference between the predicted and actual values. Lower values of MSE indicate a better fit.
Model Analysis
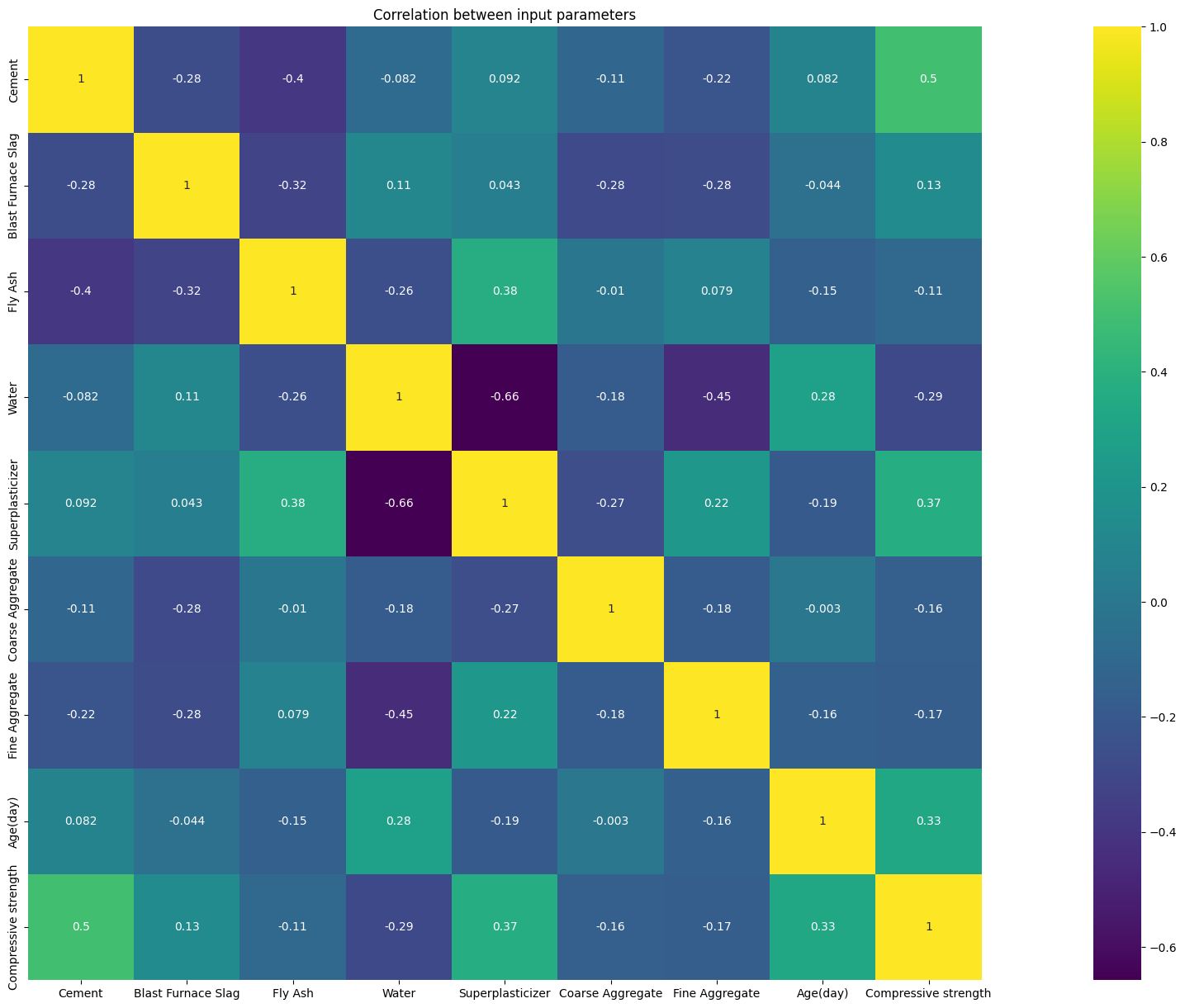
Correlation Coefficient Study
A correlation coefficient study was performed on the input parameters. The range of the correlation coefficients indicates that the input parameters can be considered to have low to moderate correlations with each other. When two or more variables are highly correlated, they might carry similar information which can lead to instability, inflated importance for those variables and could also affect model generalization abilities.
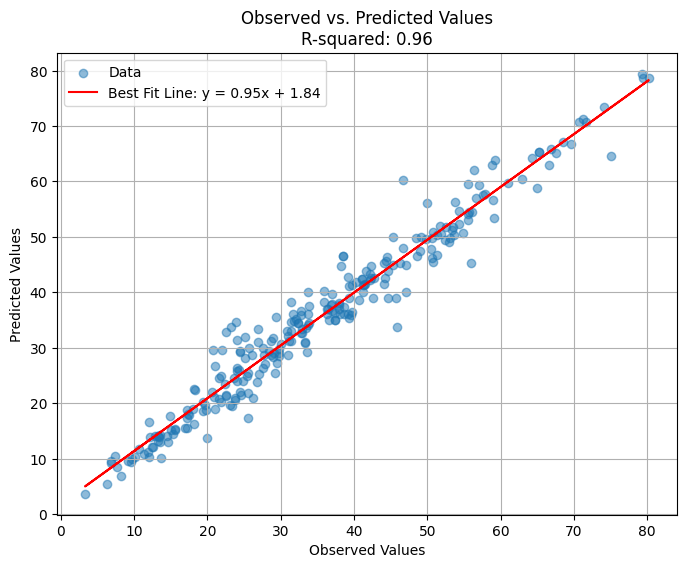
Prediction Distribution
The XGBoost Regressor achieved an impressive R-squared value of 0.96 and a mean-squared error of 11.486 MPa. The prediction distribution chart visualizes the relationship between actual and predicted compressive strength.
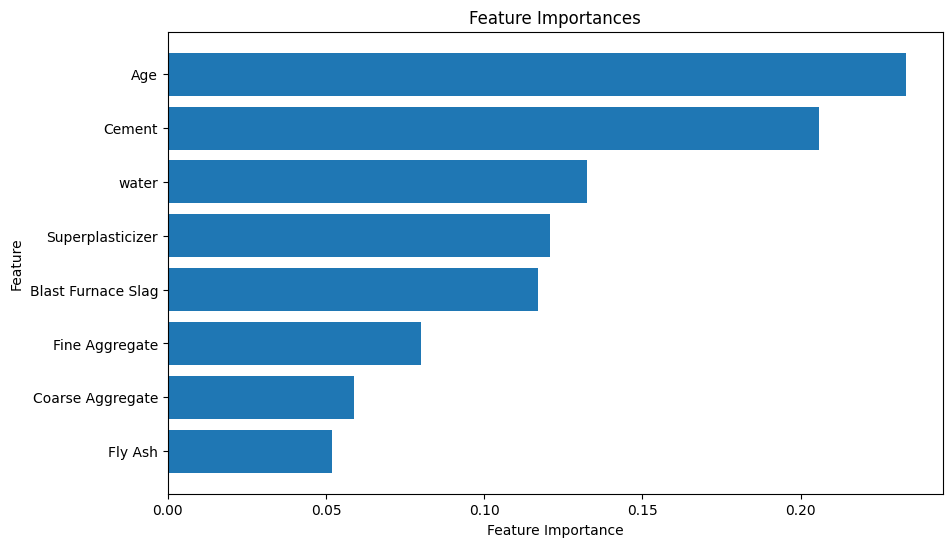
Feature Importances
An analysis of feature importances highlighted the dominant influence of age and cement content on compressive strength, constituting nearly 70% of importance.
Challenges
Deployment Bias
While machine learning models show high accuracy in predicting laboratory concrete strength, uncertainties in field-placed concrete, influenced by variable environmental conditions and operational uncertainties during curing and construction, may affect prediction accuracy. Interpretation of results should consider data quality, and high-quality field data can enhance model accuracy in practical applications.
Interpretability
Interpreting machine learning models poses challenges due to their complexity and ambiguity. Unlike traditional methods, machine learning identifies association relationships rather than causal relationships. In this particular model, while the model accurately predicts compressive strength from the input variables, there exists insufficient information about these variables; for example, cement properties, characteristics of aggregate, properties of chemical admixtures, properties of cementitious materials and curing regimes are not captured by the input variables. Regardless, the machine learning model is able to learn the implicit underlying patterns and accurately predict compressive strength from the unobserved influence of some of these underlying factors. Results from this model should thus be interpreted as associations between concrete mix ratios and compressive strength rather than causations.
Data Sparsity and Quality
The model is trained on 1030 sets of concrete samples, highlighting the need for high-quality field data to improve practical applications. Developing comprehensive data on field concrete characteristics is essential for enhancing model performance in real-world settings.
Conclusion
While machine learning models like XGBoost Regressor offer powerful tools for predicting concrete compressive strength, users must be aware of deployment challenges, interpretability issues, and the importance of high-quality field data for real-world applications.
References
- Zhanzhao Li et al. Machine learning in concrete science: applications, challenges, and best practices. Article
- Vimal Rathakrishnan et al. Predicting compressive strength of high-performance concrete with high volume ground granulated blast-furnace slag replacement using boosting machine learning algorithms. Article
- Daihong Li et al. Machine Learning-Based Method for Predicting Compressive Strength of Concrete. Article